自己搞了个小程序,需要统计一下某些内容的访问量增速,比如某个视频 10 分钟内的访问量,在内存有限的情况下(最多 8g),用 redis 来做的话,怎么做比较好?因为存在时间窗口的问题,不知道采用哪种方法比较好。
关于用户,没登录什么的,所以也不会有什么用户 id 之类的东西
- 有序集合,毫秒时间戳抗投诉服务器为 score,但是如果比较多访问的话,内存占用比较大,实际上我只想要一个数而已
- 普通的 key,但是怎么去除 10 分钟前的数据?每分钟存一次访问量数据的话,要统计一个视频的 10 分钟访问量还好,但是要统计多个的时候,就要多次读取 redis
- 有没有更好的办法? 成本有限,加内存什么的就先不考虑了吧
每分钟一个 key 呗.
key: view_count_{vid}_{minute}
然后想统计十分钟的就捞十个 key 求和
视频 id+用途后缀:
一个计数缓存:来了统计请求就自动加一。每分钟转存到归档
一个 hash 归档缓存:每分钟存入一份分钟级别统计。
至于分析,就只从归档 hash 里取值统计,按照分钟 key 去看最近十分钟的结果。统计时候主要依靠 hash 的批量命令操作来减少读取次数
直接搞个数据库存呗,这样你想怎么统计都可以了,mysql pgsql 占用内存也不大
这就是我提到的第 2 种做法了~
但问题是,我想做一个管理后台,在视频列表上,显示每个视频的访问增速,如果我一页拿 20 个视频,每个视频捞 10 个 key,20 个视频就要捞 200 个 key,虽然说用 mget 读取也只要读 20 次....但我视频越多,key 就越多了
有数据库,但是每次视频被访问就直接写数据库+1 吗?那到时候数据库写压力就很大了
i
每分钟转存到归档,归档指的是 mysql 之类的数据落地的东西?
另外每分钟转存是后台起一个脚本来做这个吗?
hash 归档缓存 就相当于只统计了 T-1 分钟的 访问数,这个倒可以接受
这是插眼的意思吗?
key 多不要紧, 查询做好分页就行.
你会不会高估了写压力? redis 都不需要,直接 mongo 一个表存就行了,查询也好查询,反正你这个表结构很简单,就视频 id 跟时间戳或者你再加个 ip,这种简单的数据,mongo 存一亿条也无压力
就是监控数据增量变化吧 用 http://www.wgstart.com 有数据监控模块 会定期扫描并生成趋势图表
忘了说了 前提是你得从数据库( mysql pgsql 等关系型数据库)用 sql 能捞到数据
目前没有配置 mongo,mongo 存一亿条磁盘占用要去到多少呢?不用 redis 纯用 mongo 来承载读写的话,mongo 大概能抗住多大的 qps ?有没有稍微具体一点的数据可以支撑一下?
redis 有 pipe, 一次全部捞出来
我知道这个
硬盘允许的话搞个单机的时序数据库哇。
如果只存我说的那三个字段,大概不到 5G 。写的话 qps 几千肯定没问题的,读取的话你可以用 redis 缓存结果,1 分钟全表查询一次就能得到统计结果
我说的归档就是第一个 key 下产生的分钟级数据,存入第二个 key 下当归档数据,然后分析时候使用第二个 key
遇到过类似的问题,说下解决的方法
假设我们需要存储视频近 10 分钟内的访问量
存储方面,我们可以把 10 分钟,分割成 10 个 1 分钟,使用 Redis 的 bitmap 来存储这 10 个量
在命令方面,redis 的 BITFIELD 命令可以对 bitmap 的多个域同时操作,对每个域支持 GET 、SET 、INCRBY 子命令,可以满足需求
如图:
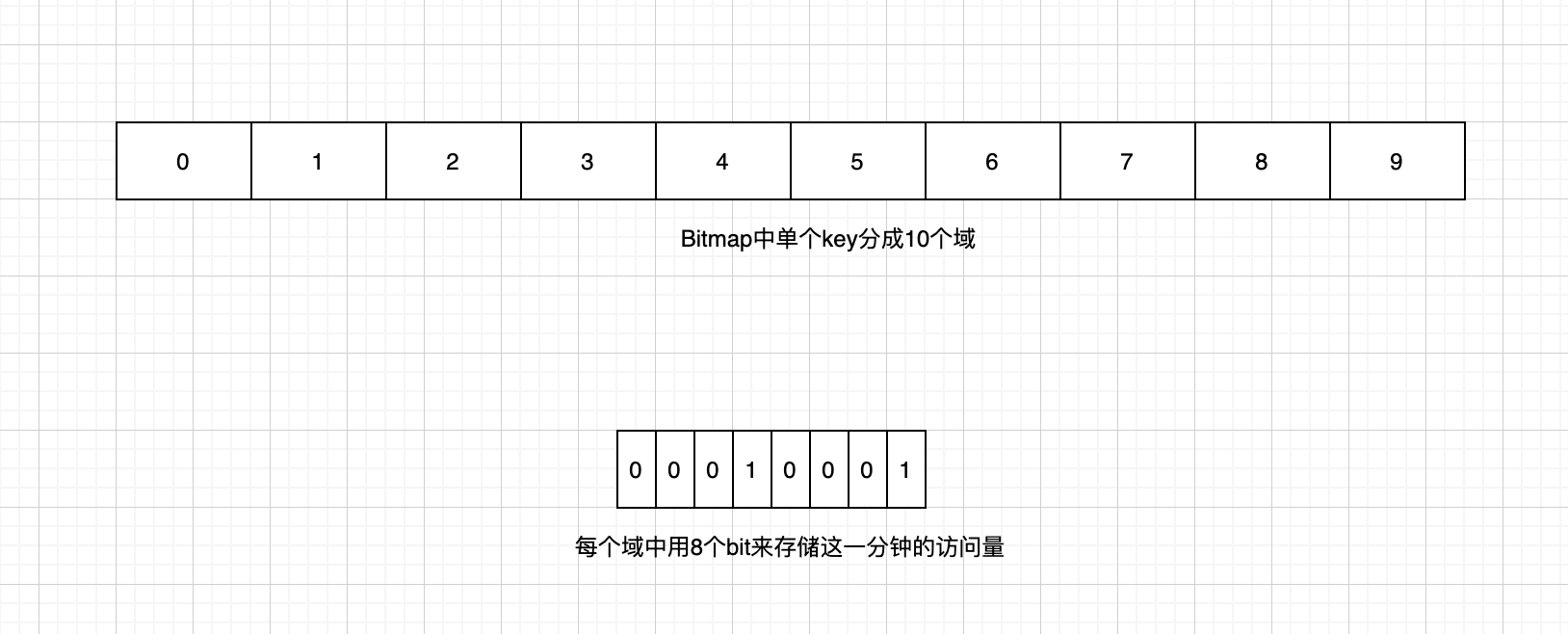
我们把 bitmap 分割成 10 个域,每个域代表 1 分钟的访问量,那么每次获取某个视频的访问量时,可以取到这 10 个域的值求和即可
假设每分钟视频的访问量的上限是 255 ( 2^8,这里是为了控制溢出,值可以无限大小,只要是 2 的正整数倍即可)
新增访问量时,只需计算应该往哪个 /哪些域( offset )里增加就可以了,如 22:13 的视频 123456 的访问量新增 17,根据时间计算 offset 为 3,命令:
`BITFIELD v:123456:cnt:bit OVERFLOW SAT INCRBY u8 0 17
这条命令返回对 offset 为 0 的域进行了+17 的操作,u8 表示按照 10 个 bit 分域,上限 255,0 标识 offset,即第 0 分钟,`OVERFLOW SAT`表示如果 incr 后的结果超过上限(这里是 2^8 ),那么结果保持在最大值 255 ( 8 位全 1 )
获取视频 123456 近 10 分钟的访问量,命令:
`BITFIELD v:123456:cnt:bit GET u8 GET u8 1 GET u8 2 GET u83 GET u8 4 GET u8 5 GET u8 6 GET u8 7 GET u8 8 GET u8 9`
这条命令会返回每个域(即每分钟)的值,求和后即为近 10 分钟的累计访问量
BITFIELD 的每个子命令的复杂度是 O(1)的,如果访问 /操作 N 个视频的近 10 分钟的访问量,也就是操作 N 次 Redis 即可
方案的优点
1. 省空间,bitmap 占用空间很小
2. 支持批量,BITFIELD 的子命令可以多个同时操作
缺点:
1. 不是严格的滑动窗口,有一定的精度损失
这个可以通过拆细粒度来解决,如 10 秒(甚至 1 秒)一个域,相应地,这样会增加一定的存储
2. 设计时需要考虑单个单位时间内的上限,超过上限时,统计不准,因为我们在溢出控制时使用了饱和算法( SAT )
这个可以在设计初期尽量预留一个保险的值,当然了,越大的话,存储也会越大
3. 对于读写分离的场景(即读从写主),BITFIELD 被 Redis 标识为写命令,所以所有的 BITFIELD 都会在主节点上执行
这个问题我们遇到了,但没有造成很高的负载,所以没有处理;不过阿里云有篇文章可以参考: https://developer.aliyun.com/article/757841
这种方案的话,还不如先写到 redis 一分钟同步一次数据到 mysql,基本没有写压力,方案上更趋近于这个
嗯嗯,这种可以考虑一下
看懂了大部分,但疑问是下一个 10 分钟的时间窗口,是另起新的 key 统计吗?还是将旧的清零?比如 10:59 分 过渡到 11:00 的时候,此时 bitmap 上 0 这个 field 还是存储着 10:50 的统计?还是怎么样
你这小程序多大的量,还担心数据库写入太频繁。用户访问一次,写入一条记录,大多数情况下没什么问题
总视频数、每 10 分钟总的访问量说下量级吧,应用场景是怎样的,感觉你想得太多了。
比如「我想做一个管理后台…」,你管理后台每秒能刷几千次啊,还能被刷爆?
而如果是面向公众用户的场景,你的需求也不需要「实时、精确地计算出访问增量」,每分钟统计一下就行了。
最后,这种情况比较常见的做法是使用时间轮,比如选一个比 10 大又能被 60 整除的数,例如 12 。将当前的分钟数对 12 取模,然后每个 key 记录这一分钟的数据。每到一个新的一分钟,就把 11 分钟前的 key 删了。要获取数据时,就取当前和之前的 10 个 key 。
至于数据结构选啥,根据你的视频量级、视频数是否恒定、id 是否连续等而定,不同的方案内存差别很大。比如一楼提到的 view_count_{vid}_{minute},这种实现不用看也知道内存扛不住。
用 hash 类型存储,每个文件一个 key 。这个 key 下面每 10 分钟新增一个 hash key,在这个时间段里,每访问一次这个 hash key 的 value +1 。
单个视频的访问量用两个 key 来存储,过期时间设置成两个周期,也就是 20 分钟
写入时,每次都对当前周期内的 key 写入
读取时,读取上个周期的后半部分和这个周期的前半部分
如:
现在是 10:56,则目前数据库中的 key 有两个,v:${id}:cnt:bit:1040 (过期时间还有 4 分钟) 和 v:${id}:cnt:bit:1050 (过期时间还有 14 分钟),1040 代表 10:4X 周期内的计数,10:50 代表 10:5X 周期内的计数
若 10:56 新增 10 个,则对 v:${id}:cnt:bit:1050 内第 6 个域 incr 10 即可
若读取最近 10min 的访问量,则取前一个 key 的后 3 个域( 10:47 、10:48 、10:49 )和当前 key 的前 7 个域( 10:50 ~ 10:56 ),然后求和
这样的话就避免了你提到的问题,但增加了一倍的存储(两个 key )
再复杂一点的方案,单 key 中前 N 位用 1 个单独的域,记录上次写入时间,每次写入前,根据当前时间和上次写入时间判断是否要重置之前的某个 /某些域,然后再进行写入+(重置)的操作。这样的话,存储能降到一个 key,但写入时多了一次操作,时间换空间了,适用于 写少读多的场景,所以最好是聚合写
每次请求写到 log 里用 shell 统计都很快的。先实现出来,然后在看满足不满足性能要求和功能需求,然后在看怎么优化改进方案。
日活目前在 1w 多有,预计会增长至 10w
就算用一楼的办法,每分钟也只是同一个普通的 key 。而且也会删掉,”不用看也知道内存扛不住“ 是不是太武断了些....我觉得抗住是没有问题的...
那这样子就没有了时间滑动窗口了,我也不会问这个问题了
是的,今天想到了这个,直接解析 nginx 的 log 也是个办法
或者将每一条视频播放请求发到队列用 flink 的滑动窗口去统计,你那服务器的配置干这个完全不在话下。
你要怎样滑动?以什么为单位?要以分钟为单位滑动,按分钟计数,按秒滑动就按秒计数。不还是一样的道理吗?
最近有个类似的需求,感谢
说个 100K QPS 级的方案:
1. 在内存(或 redis )里记数,定时 (比如 10s) flush 到持久存储 (mysql 或 influxdb) 并 reset 内存中的计数器
2. 查询的时候就是指定时间范围 SUM() 聚合了
3. 定期清理持久存储中的历史数据
4. 如果需要保留长时间历史数据,需要在持久存储那端做降采样
关键是 1. 写入的时候不要每次请求都落盘 2. 查询的时候要能用上 rdbms 的查询能力
如果是单纯的统计增速,那用时序数据库不是很合适么?比如用开源版的 influxdb 。
换成一分钟之后,那这不就是一楼说的那种做法吗?
楼主你有没有搞清楚自己的需求?需求确定了,数据结构自然就能确定了。数据结构确定了,存储方案自然就能确定了。即使有问题,至于连问题是什么都说不清吗?
嗯嗯,有想过这个方法,历史数据可以放到冷数据表,但是这种方法如果要查更长的近 x 分钟时间的数据,视频越多,存储量就越多了,不知道你这个量级,一个固定时间内(比如 1 个小时),持久存储里面的记录数有多少?存储结构是怎么样的?
比如 10s flush 一次到 db 的话,一分钟就相当于有 6 条记录了?
聊场外就没意思了,需求描述得挺清楚的了,就是要在内存有限的情况下用 redis 统计近 10 分钟的数据,做法不同数据结构不同,你后面说的这种做法和一楼二楼说出来的没有本质的区别,问题也在描述的地方说了,存在滑动窗口的问题,你的第一条回复本质是固定的时间窗口,我只是回复你这样做的话不满足我的需求,请问怎么看出我不了解需求和数据结构的问题呢?
嗯嗯我加入备忘研究一下
你最好先熟悉 redis 的内存占用再来臆测。一楼的方案内存占用要多 1~2 个数量级。
关键是我没有看出来你的方案和一楼的方案有什么本质的区别,臆测倒没有,你说扛不住也要说说你的理由和分析吧?
对不起,一开始没有 get 到你全部的意思,我之所以会这么说,是因为用一楼的方案,也可以做到你说的时间轮的类似效果,只是一楼少了定时删除旧缓存的做法,加上之后,我觉得和你说的没有太本质的区别,始终维护的是一个时间段内的数据
看需求有点云里雾里的,如果是我的话我会用 HyperLogLog 统计,最大占用 12k,会有 0.81%左右的误差但很高效
要在内存有限的情况下用 redis 统计近 10 分钟的视频访问量,转发数等数据,HyperLogLog 主要是去重,场景不对
redis 设置一个过期时间( 10 分钟),然后设置他值为 1 。 判断这个 redis 存在就累加。没有存在就重新设置
这种不太符合时间滑动窗口的需求哈
设置 bitmap 的存储大小,例如 1 -N 分钟,单个 Key 的长度为 200(假设),那么第一个 key 存储时,为 name_1,第二个为 name_2,同时失效第一个,保证永远只会存在一个 key,统计时,直接 200 * n +当前 name_key 的长度;