新闻资讯
不懂就问:如何正确设计一个订单号?
- 0次
- 2021-06-03 18:42:43
- idczone
大带宽服务器目前可能主要是考虑体量大了,查询索引优化问题。大牛们你们各家都是咋做的?
参考: 如何正确设计一个订单号???
我记得推特啥的好像有一个短一点的
看看美团 leaf 取号器
生成订单号的函数如下:
function build_order_no(){
return date('Ymd').substr(implode(NULL, array_map('ord', str_split(substr(uniqid(), 7, 13), 1))), 0, 8);
}
对外的订单号应该是纯数字的,方便用户查看和售后。
看业务需求, 订单号也不能纯粹的无意义啊, 比如我们做自动售货机的, 订单号上就要携带售货机编号,货道等数据
订单号应至少满足以下需求:
1.纯数字,或者字母只做前缀用,方便售后等,
2.自增,
3.非连续,反正竞争对手间隔一定时间下单,根据订单号推送平台订单量,
4.高并发
5. ...
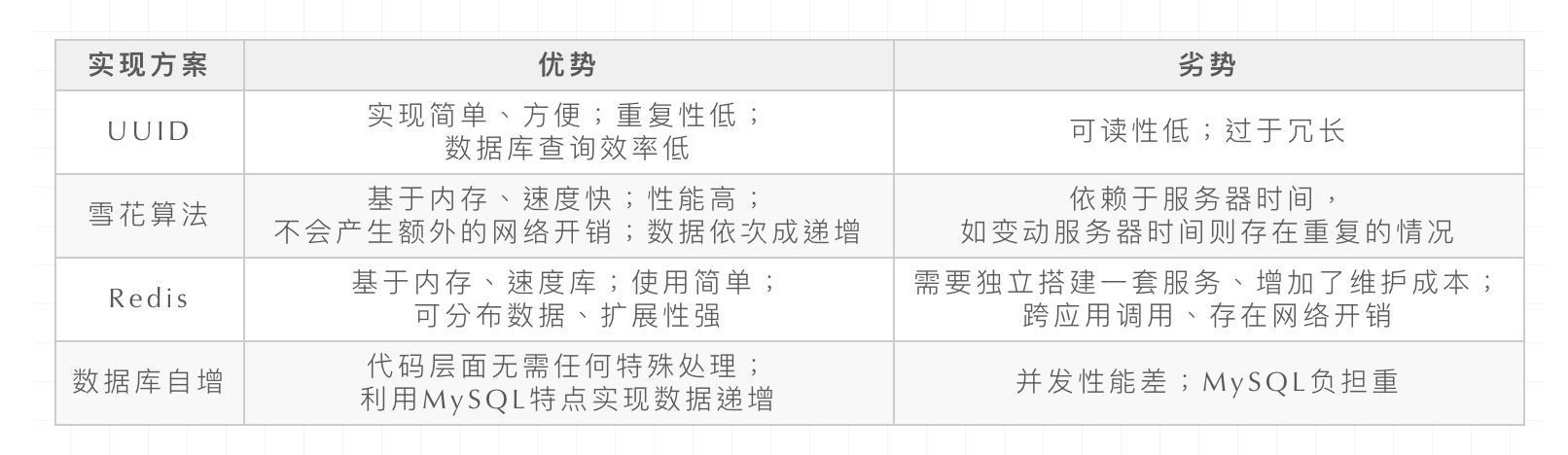
综上,推荐推特的雪花算法,或者以此为基础的美团百度变种。
github.com/sony/sonyflake 比推特的可用时间长
The lifetime (174 years) is longer than that of Snowflake (69 years)
不推荐自增型的,因为对手能知道你的体量。
雪花比较好
一天生成好几千万的单号没问题
看你的订单号要不要有具体的意义,比如说,年-月-日-时-分-秒-结算柜台编号,就可以简单的保证 ID 不重复,且随着时间增加。(同时不可能在一个柜台产生两个订单)
如果不需要特别的意义,只需要是唯一 ID,那么雪花算法挺好的,正常情况下也不会改服务器时间。查询效率和数据库自增差距不大。
只要存储类型是数字,且有一定的增长趋势,那么查询效率都还可以的。别往里面丢字符就行。
内部订单号不应以任何方式对外(包括最终用户和非运维的操作员)暴露,而仅仅用于系统内部,唯程序和调试时可读,如此一来可以使外部订单号的设计较为宽松,且任何时间可以修改(还不会像 BV 号那样秒破译)
内部订单号需要:数字格式的纯数字,方便索引和传输;生成过程高并发
外部订单号需要:尽可能提供责任归属信息,方便任务分发;没有歧义字符(无论声、光);生成过程高并发;难以遍历;最好带校验位提供冗余信息
显然,前者本机 ID+自增 ID 完全可以承载,或者雪花;后者依赖具体情况,典型是身份证号码,每段含义明确,不是纯数字也没有关系,无论是读出来还是写出来,X 都不会造成歧义,并且最后一位是校验位提供了冗余信息错误的身份证号码可以被离线检测出来。
那只能适应于订单号不需要索引的场景
顺序生成数字,考虑分布式就多服务器间隔顺序生成
然后做一个显示变换,在显示给用户和用户传入到后台进行一次 encode/decode
好想法!学到了。有一个问题,“没有歧义字符(无论声、光)” 是指什么? 0oO ilIL 这种?
雪花算法有优化版,可以解决过长和时间回调的问题
差不多,具体得看你对歧义有多大忍耐程度
像无线电,017 都要特殊读音(洞、幺、拐),还有北约音标字母
最好还要 OCR 友好,这方面可能需要字体的帮助。
——
顺便好像校验位还有个好处,如果上手直接尝试遍历的,很快会因为校验位不正确被发现。如果校验位不正确请求比例很高,则可以很快地发现遍历者,甚至在流量实际接触到数据库之前就能被防下来。意外的好处,虽然实际用途不大(
我想起来我之前设计的订单号 公司首字母+年月日+后六位时间戳+4 位随机字母。 哈哈哈,真的简单
自增 id 不要参与业务
我做了个自定义单号生成器,用户可以自定义规则来生成任何他想要的编号。想顺序就顺序,想乱序就乱序,绝不会重复。
还有个方案是做个订单号服务,提前生成好再分配,很多短网址是这么做的
电商研发提醒你,不要用自增 id,一不注意就被脱裤了
先有订单 再有订单号 不用设计,用来 verbose 。至于查找,得依赖你查找的范围,保证查找范围内唯一即可。
举例:
有一个订单,创建时间 123,客户 250,主键 10000,查找范围(使用场景)是客户登录时根据单号查询订单
那么生成一个 verbose 的订单号可以=250+123+随机,当然保存的时候需要验证订单号是否已经占用
查找时验证头是否是当前客户,不匹配者订单号不合法,合法就去数据库里查即可
总的来说不需要刻意设计,因为没有订单号也没关系,订单在数据库里能调出来就行,它只是 verbose